
Исследование: государственный контроль над СМИ влияет на ответы ИИ-чатботов
Задайте одному и тому же ИИ-чатботу одинаковый политический вопрос на двух разных языках — и вы можете получить два совершенно разных ответа. Исследование, опубликованное в среду в журнале Nature, предлагает убедительное объяснение: правительства способны косвенно влиять на большие языковые модели, формируя медиапространство, на котором эти системы обучаются.
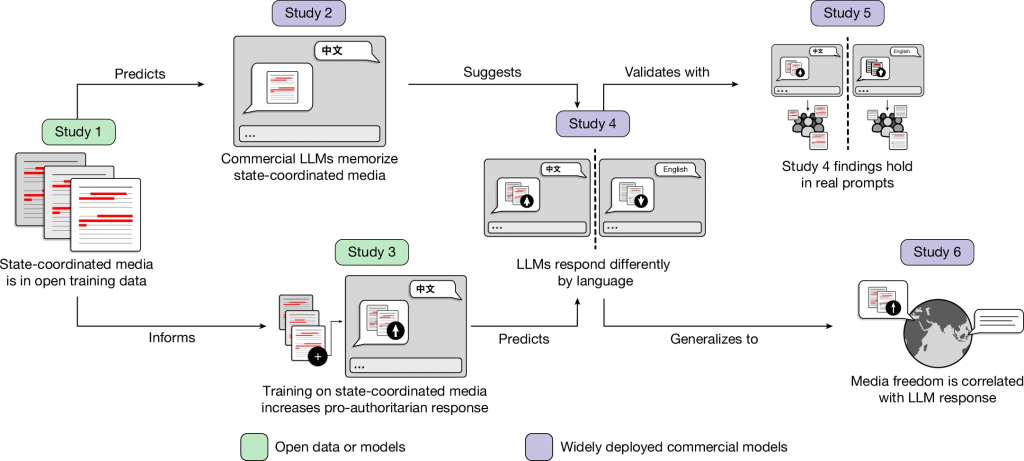
Как пропаганда попадает в обучающие данные
Исследование, проведенное Ханной Уайт из Орегонского университета совместно с коллегами из Университета Пердью, Калифорнийского университета в Сан-Диего, Нью-Йоркского и Принстонского университетов, включает шесть экспериментов, прослеживающих путь от государственных СМИ до ответов чат-ботов. Ученые обнаружили, что материалы, созданные и распространяемые под контролем китайского государства, встречаются в открытых обучающих датасетах для языковых моделей значительно чаще, чем материалы из независимых источников, — по данным исследования, в 41 раз чаще, чем статьи китайскоязычной Википедии. Кроме того, исследования показали, что коммерческие модели запоминали характерные для пропаганды последовательности слов намного лучше, чем фразы из других документов.
Чтобы проверить, может ли присутствие пропаганды в обучающих данных причинно влиять на поведение модели, команда провела дополнительное обучение модели с открытыми весами на материалах китайских государственных СМИ. Результат оказался показательным: модель стала давать более положительные ответы на запросы о китайских политических институтах и руководстве страны. При этом запросы к коммерческим моделям на китайском языке, а не на английском, давали ответы, более благоприятные для китайского правительства, — эта закономерность сохранялась даже в случае запросов, сформулированных реальными китайскоязычными пользователями этих систем.
Межнациональная закономерность
Результаты исследования выходят далеко за рамки Китая. В ходе межнационального анализа 37 стран, где национальный язык преимущественно используется в пределах одного государства, было установлено: модели описывали правительства и институты стран с более жестким медиаконтролем благосклоннее на родном языке этих стран, чем на английском. Выявленная закономерность свидетельствует о том, что данный механизм не является особенностью какого-либо одного авторитарного режима, а представляет собой структурную черту того, как языковые модели усваивают информацию из интернета.
Предупреждение об информационном конвейере ИИ
Уайт, подробно изучавшая китайскую государственную пропаганду, ранее установила, что написанные по государственному заказу пропагандистские материалы появляются в китайских газетах примерно в 90% случаев, а в чувствительные периоды до 30% материалов на первых полосах размещаются по указанию властей. Новое исследование, опубликованное в журнале Nature, утверждает, что та же пропагандистская инфраструктура теперь распространяет свое влияние на системы ИИ, которыми пользуются миллионы людей по всему миру.
Исследование выходит на фоне растущей обеспокоенности тем, как большие языковые модели обращаются с провластными СМИ. В мартовском докладе Фонда защиты демократий говорится, что провластная пропаганда присутствовала в 57% ответов чат-ботов на вопросы о международных конфликтах, тогда как платная качественная журналистика из демократических стран структурно проигрывает в конкурентной борьбе за включение в обучающие данные. Авторы исследования в Nature предупреждают, что по мере распространения генеративного ИИ у государств и влиятельных институтов появляется «все больше стратегических стимулов» использовать контроль над СМИ для воздействия на результаты работы языковых моделей.
Абдуазиз Хидиров, УзА



